
Introdction
What is Machine Learning
机器学习:计算机通过数据和计算获得一定技巧的过程。
技巧:指的是在某些事情上表现更加出色,比如预测、识别等等。
Why using Machine Learning
一些数据或者信息,人来无法获取,可能是一些人无法识别的事物,或是数据信息量特别大;
人的处理满足不了需求,比如:定义很多很多的规则满足物体识别或者其他需求;在短时间内通过大量信息做出判断等等。
When to use Machine Learning
存在一个模式或者说表现可以让我们对它进行改进提高;
规则并不容易那么定义;
需要有数据。
Components of Machine Learning
一个机器学习问题,主要由以下几部分构成:
- 输入: $\textbf{x} \in \mathcal{X}$
- 输出: $\textbf{y} \in \mathcal{Y}$
- 目标函数:$f: \mathcal{X} \rightarrow \mathcal{Y}$
- 数据:$\mathcal{D} = \{ (\textbf{x}_1, \textbf{y}_1), (\textbf{x}_2, \textbf{y}_2) \ldots (\textbf{x}_N, \textbf{y}_N),\}$
- 假设:$g: \mathcal{X} \rightarrow \mathcal{Y}$
目标函数 $f: \mathcal{X} \rightarrow \mathcal{Y}$ 将输入 $\mathcal{X}$ 映射为输出 $\mathcal{Y}$,我们手头有一组由 $f$ 生成的数据 $\mathcal{D}$,目标就是通过对数据的学习,得到一个假设 $g: \mathcal{X} \rightarrow \mathcal{Y}$,使得 $g$ 与 $f$ 尽量接近。
Learning Flow
以一个更加详细的流程图来说明这一过程:
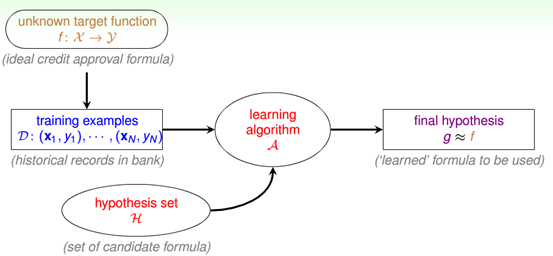
目标函数 $f: \mathcal{X} \rightarrow \mathcal{Y}$ 将输入 $\mathcal{X}$ 映射为输出 $\mathcal{Y}$,$\mathcal{X}$ 与 $\mathcal{Y}$ 在一起构成了数据 $\mathcal{D}$,我们的目标就是通过对数据的学习,得到一个假设 $g: \mathcal{X} \rightarrow \mathcal{Y}$,使得 $g$ 与 $f$ 尽量接近。为此,我们必须选定一个假设空间 $\mathcal{H}$,然后使用算法 $\mathcal{A}$,选择 $\mathcal{H}$ 里的一个假设作为 $g$。
在这里有几个需要注意的地方:
- 机器学习的输入在这个流程图中就变成了两个部分,一个是训练样本集,而另一个就是假设空间 $\mathcal{H}$。
- 我们所说的机器学习模型在这个流程图中也不仅仅是算法 $\mathcal{A}$,而且还包含了假设空间 $\mathcal{H}$。
上图还是一个相对比较简单的机器学习流程图,在往后的文章中会不断的根据新学的知识继续扩展这幅图的元素。
Machine Learning and Other Fields
- ML VS DM
两者密不可分:
- 两者是一致的
能够找出的有用信息就是我们要求得的近似目标函数的假设。 - 两者是互助的
能够找出的有用信息就能帮助我们找出近似的假设,反之也可行。 - 两者的区别
传统的数据挖掘更关注与从大量的数据中的计算问题。
ML VS AI
机器学习是实现人工智能的一种方式。ML VS Statistic
- 统计是一种实现机器学习的方法。
- 传统的统计学习更关注与数学公式,而非计算本身。

